L'Algoritmo e i Linguaggi di Programmazione
Le caratteristiche degli Algoritmi
Procedimento di esecuzione dell'Algoritmo
Dati di Input Output e Interni
Metodi di descrizione degli Algoritmi
Schema blocchi usati nei flow-chart
Gli schemi di composizione fondamentali
Strutture di controllo fondamentali
Principali varianti delle strutture di controllo
Flow chart illustrativo dell'esempio
Esempio di algoritmo non strutturato
Versione strutturata dell'algoritmo precedente
Linguaggi strutturati e non strutturati
Il metodo dell'analisi Top-Down
Consigli per l'uso dell'editor
Programmi in linguaggi Interpretati
Programmi in linguaggi compilati
Vantaggi e svantaggi di Compilatori e Interpreti
Realizzazione di un programma con un compilatore
La traccia del programma o Trace
![]()
![]()
Simbologia usata nel metodo Warnier
Simbologia usata nel metodo Jackson
I CASE (Computer Aided Software Engineering) per la realizzazione di Programmi
Ricorsione semplice e indiretta
Tipi di problemi in base alla computabilità
Complessità dei problemi e problemi intrattabili
La Macchina di Turing Universale
Schema della macchina di Turing
INFORMATICA - PROGRAMMAZIONE DALL'ALGORITMO AL PROGRAMMA
GLI ALGORITMI
Per poter risolvere un certo problema bisogna fornire al computer il programma adatto. In altre parole, è necessario conoscere (indipendentemente dal calcolatore) la procedura di risoluzione. Il computer infatti può soltanto velocizzare le operazioni e padroneggiare una grande quantità di dati, ma esegue soltanto quello che gli viene indicato esplicitamente. Prima di tutto bisogna quindi determinare l'algoritmo, cioè l'elenco delle istruzioni da eseguire di volta in volta per raggiungere la soluzione del problema. L'algoritmo può essere descritto con vari metodi, discorsivi o grafici; il metodo più noto è quello che utilizza i flow-chart o diagrammi a blocchi. Il programma vero e proprio si ottiene codificando l'algoritmo in un linguaggio di programmazione, cioè scrivendo le istruzioni dell'algoritmo secondo la sintassi del linguaggio scelto.
L'ALGORITMO E I LINGUAGGI DI PROGRAMMAZIONE
L'algoritmo rimane valido indipendentemente dal linguaggio di programmazione usato per la codifica del programma? Si può rispondere di sì, se ci si limita all'insieme dei linguaggi imperativi, cioè quelli in cui bisogna specificare esattamente il tipo di procedimento da seguire. Esistono infatti anche linguaggi di tipo molto diverso: per esempio quelli in cui non si deve specificare come risolvere un certo problema, ma soltanto ciò che si vuole ottenere (linguaggi logici) o linguaggi in cui ogni entità del programma costituisce un oggetto e il modo in cui quest'ultimo deve funzionare viene descritto da "metodi" legati all'oggetto (programmazione ad oggetti). Comunque i linguaggi più diffusi come BASIC, PASCAL, COBOL, C e molti altri, che potremmo chiamare tradizionali, sono molto simili tra di loro nella struttura, pur presentando differenze nella sintassi delle varie istruzioni. In generale un algoritmo per la soluzione di un problema può quindi essere codificato in un linguaggio o in un altro con poche varianti. In questo capitolo si parlerà della descrizione degli algoritmi in modo indipendente dai linguaggi di programmazione.LE CARATTERISTICHE DEGLI ALGORITMI
Si può chiamare algoritmo solo un insieme di istruzioni che ha alcune caratteristiche particolari: - è eseguibile - è finito - ha un effetto osservabile - è deterministico - è generale. l'algoritmo deve essere composto da istruzioni che l'esecutore sia realmente in grado di seguire; inoltre il procedimento deve terminare sempre in un tempo finito, producendo dei risultati che si possano descrivere. I risultati devono essere sempre uguali, se si parte dagli stessi dati iniziali; quindi non ci può essere nulla di casuale. L'algoritmo inoltre non deve risolvere un singolo caso particolare, ma tutta una serie di problemi dello stesso tipo.PROCEDIMENTO DI ESECUZIONE DELL'ALGORITMO
Parlando di un algoritmo bisogna distinguere tra la sua descrizione e la sua esecuzione. La descrizione è la lista delle istruzioni, che comprende tutti i casi possibili per trattare una classe di problemi; l'esecuzione è l'applicazione a un caso particolare, partendo da dati iniziali noti. Il processo di esecuzione può essere fisso (se bisogna eseguire sempre le stesse istruzioni per qualsiasi insieme di dati di partenza) o variabile (se l'esecuzione di una o più istruzioni è legata al fatto che si verifichi o meno qualche condizione particolare); se il procedimento di esecuzione è variabile le istruzioni da seguire dipendono da dati iniziali del caso preso in esame, e l'algoritmo descrive un insieme di sequenze di esecuzione diverse.ALGORITMO = DATI + ISTRUZIONI
Una definizione più pratica di algoritmo è quella che lo descrive come un procedimento che permette di ottenere dei risultati (dati in uscita o di output) partendo da alcuni dati iniziali (dati di ingresso o input). L'algoritmo non è soltanto un insieme di istruzioni: una componente fondamentale è costituita dai dati; quindi una fase essenziale della stesura dell'algoritmo è la scelta dei dati da utilizzare.ALGORITMI EQUIVALENTI
Due algoritmi si dicono equivalenti se per ogni combinazione di dati iniziali producono sempre gli stessi risultati, pur seguendo istruzioni diverse.![]()
![]()
I DATI
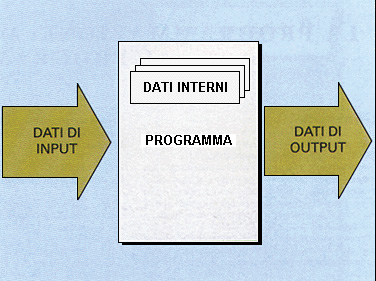
I dati permettono la comunicazione tra l'utente e il programma (o meglio tra l'utente e l'esecutore del programma, cioè nel nostro caso il computer, con la sua CPU). L'utente fornisce al programma i dati iniziali e ne riceve i risultati, dopo l'applicazione dell'algoritmo. I programmi vengono realizzati proprio allo scopo di ottenere certi risultati in modo automatico dal computer invece di utilizzare con procedimenti manuali.DATI DI INPUT OUTPUT E INTERNI
I dati di input sono quelli che l'utente deve fornire al programma per l'esecuzione; devono quindi essere noti al momento dell'esecuzione; non ha quindi importanza conoscerli al momento della descrizione dell'algoritmo, anzi l'algoritmo non si deve basare su un caso particolare ma deve essere generale, cioè valido per qualsiasi insieme di valori di input. I dati interni sono quelli utilizzati all'interno dell'algoritmo, predisposti dal programmatore, ma di nessuna importanza per l'utente del programma.TIPI DI DATI STANDARD
Alcuni tipi di dati sono standard, cioè disponibili in generale per tutti i linguaggi. - Tipo numerico Comprende i numeri e può essere suddiviso ulteriormente in numeri interi (i numeri senza pari decimali, con il segno + o -) e reali (i numeri con la virgola e una parte decimale, sono sempre con il segno + o -); sui dati numerici sono definite tutte le operazioni aritmetiche ed operazioni di confronto.Tipo alfanumerico Comprende i dati composti da caratteri alfabetici, cifre e caratteri speciali (gli altri caratteri presenti sulla tastiera, come le parentesi, l'asterisco, il simbolo di percentuale, lo spazio vuoto, ecc.); i dati alfanumerici vengono in genere anche chiamati stringhe (stringhe di caratteri) e possono essere confrontati per vedere quale dei due precede l'altro secondo l'ordine stabilito dal codice usato (per i personal computer il codice ASCII); può inoltre essere possibile combinare insieme più stringhe (per ottenere una specie di parole composte) o estrarne delle parti (i primi o gli ultimi caratteri, la parte centrale ecc.) - Tipo booleano Un dato booleano può assumere solamente due valori, chiamati Vero e Falso (True e False); sui dati booleani sono definite le operazioni logiche (operatori NOT, AND e OR).
METODI DI DESCRIZIONE DEGLI ALGORITMI
Ci sono vari metodi per descrivere gli algoritmi, alcuni discorsivi altri grafici. Tra i metodi discorsivi il più utilizzato è quello della pseudocodifica in cui le istruzioni vengono descritte in un linguaggio molto simile a quello quotidiano. Tra i metodi grafici il più famoso è senz'altro quello che utilizza i flow-chart (chiamati anche diagrammi a blocchi o diagrammi di flusso del programma).Schema blocchi usati nei flow-chart

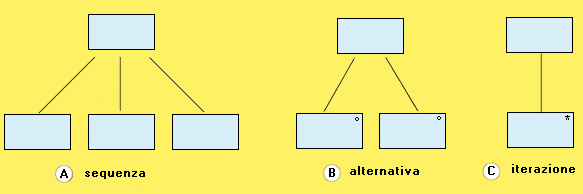
GLI SCHEMI DI COMPOSIZIONE FONDAMENTALI
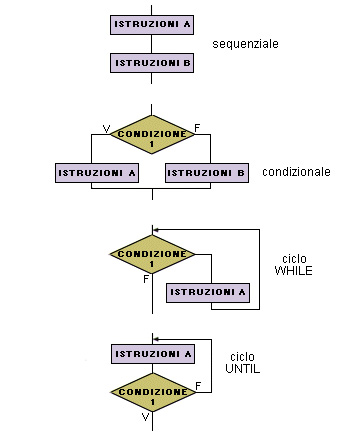
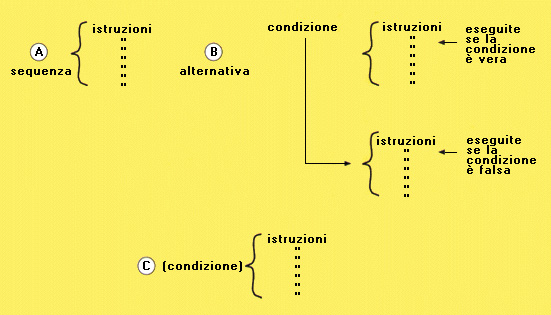
Le istruzioni di un algoritmo possono richiedere effettivamente l'esecuzione di una operazione (come quelle per risolvere le operazioni aritmetiche o le istruzioni di input/output), o possono servire soltanto per controllare il flusso di esecuzione del programma. Le istruzioni del primo tipo vengono chiamate istruzioni effettive, quelle del secondo tipo istruzioni di controllo. Per descrivere qualsiasi algoritmo basta usare una combinazione delle tre strutture di controllo, chiamate schemi di composizione fondamentali: - la struttura sequenziale in cui le istruzioni vengono indicate una dopo l'altra nell'ordine in cui devono essere eseguite; - la struttura di selezione o condizionale in cui le istruzioni vengono separate in due gruppi che vengono eseguiti in alternativa in base al verificarsi di una condizione; - la struttura iterativa o ciclica in cui viene indicato un gruppo di istruzioni da ripetere più volte, terminando in base al verificarsi di una condizione. Ogni gruppo di istruzioni presente in una struttura condizionale o iterativa può a sua volta comprendere istruzioni di qualsiasi tipo, comprese altre strutture condizionali o cicliche; si dice in questo caso che le strutture sono nidificate (una interna all'altra).STRUTTURE DI CONTROLLO FONDAMENTALI
- Struttura sequenziale istruzioni A istruzioni B - Struttura di selezione o condizionale se condizione 1 allora istruzioni A altrimenti istruzioni B fine se - Strutture iterative o cicliche - ciclo WHILE mentre condizione 1 esegui istruzioni A fine mentre - ciclo UNTIL ripeti istruzioni A finché condizione 1Strutture di controllo fondamentali
LE PRINCIPALI VARIANTI
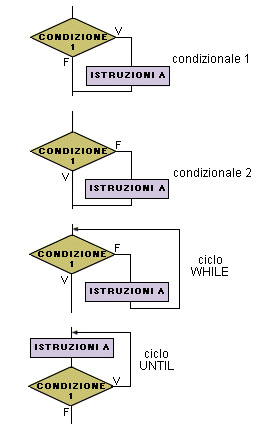
- Struttura di selezione o condizionale La struttura può avere un solo ramo se condizione 1 allora istruzioni A fine se La condizione può essere negata se non condizione1 allora istruzioni A fine se - Strutture iterative o cicliche La condizione può essere negata - ciclo WHILE mentre non condizione 1 esegui istruzioni A fine mentre - ciclo UNTIL ripeti istruzioni A finché non condizione 1Principali varianti delle strutture di controllo
L'INDENTAZIONE
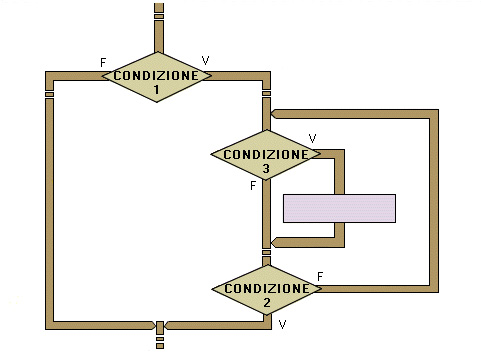
L'indentazione è un metodo di scrittura, utilizzato sia per la pseudocodifica sia per la scrittura dei programmi in linguaggio di programmazione, che permette di evidenziare gli schemi di composizione adottati per la stesura dell'algoritmo e quindi facilita la comprensione del flusso di esecuzione dell'algoritmo stesso. Il metodo consiste nello scrivere le istruzioni dei cicli o dei rami delle strutture condizionali, spostandosi verso destra di alcune colonne a ogni livello di nidificazione. Molti editor offrono funzioni che facilitano la scrittura dei programmi con il metodo dell'indentazione; infatti il ritorno a capo può essere fatto posizionandosi sotto il primo carattere della riga precedente anziché sul primo carattere della nuova riga.ESEMPI
Alcune righe di pseudocodifica scritte con il metodo dell'identazione.
Se condizione1 allora ..... ripeti se condizione3 ..... fine se finché condizione 2 altrimenti ..... fine se
Flow chart illustrativo dell'esempio
LA PROGRAMMAZIONE STRUTTURATA
La programmazione strutturata è un insieme di regole per la stesura degli algoritmi in modo che risultino più facilmente comprensibili a una revisione successiva o da parte di persone diverse. Un algoritmo si dice strutturato se utilizza soltanto gli schemi di composizione fondamentale (la struttura sequenziale, la struttura di selezione o condizionale, le strutture cicliche o iterative). In precedenza gli algoritmi venivano descritti facendo largo uso di istruzioni di salto (le famose GOTO) che indicavano l'istruzione successiva da cui proseguire l'esecuzione; le istruzioni di salto si intrecciavano in modo da rendere molto difficile la comprensione del flusso di esecuzione complessivo. La programmazione strutturata, in pratica, bandisce l'utilizzo delle istruzioni di salto e richiede una "struttura" più chiara dell'algoritmo anche nella mente del programmatore. Il fatto che si possa realmente descrivere ogni algoritmo usando soltanto gli schemi di composizione fondamentale è garantito dal teorema, di Bohm-Jacopini (o teorema della programmazione strutturata). Il teorema di Bohm-Jacopini afferma in pratica che qualsiasi algoritmo non strutturato, che utilizza cioè delle istruzioni di salto all'interno del programma, può essere trasformato in un algoritmo strutturato, usando eventualmente delle variabili aggiuntive, chiamate flag o segnalatori.Esempio di algoritmo non strutturato
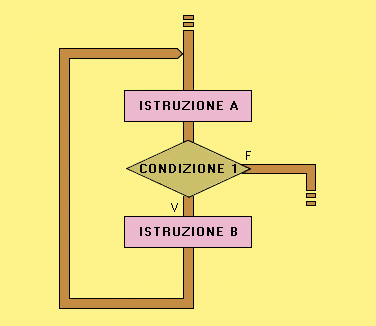
Versione strutturata dell'algoritmo precedente
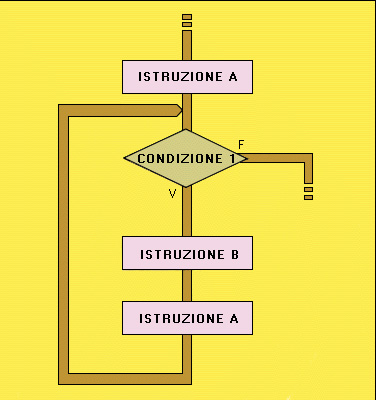
LINGUAGGI STRUTTURATI E NON STRUTTURATI
I primi linguaggi di programmazione offrivano ben poche istruzioni di controllo; il flusso del programma veniva solitamente descritto con istruzioni IF, che servivano per testare il valore di una condizione, e istruzioni GOTO che servivano ad effettuare un salto in un punto diverso del programma. Linguaggi di questo tipo si dicono non strutturati. I linguaggi nati invece con istruzioni adatte a codificare gli schemi di composizione fondamentale vengono detti linguaggi strutturati. Per esempio il Pascal è un linguaggio strutturato; il Basic e il Cobol sono stati per lungo tempo linguaggi non strutturati ma ormai le ultime versioni di tutti i linguaggi offrono le istruzioni necessarie per la programmazione strutturata e l'istruzione di salto si avvia ad essere dimenticata.IL METODO DELL'ANALISI TOP-DOWN
L'analisi top-down (dall'alto in basso) è un metodo di programmazione che permette di descrivere l'algoritmo prima in modo generale e poi sempre più in dettaglio, fino ad ottenere la versione definitiva. In questo modo la stesura dell'algoritmo risulta molto più semplice; un problema complesso può essere scomposto in una serie di sottoproblemi più semplici, che vengono affrontati separatamente, raggiungendo la soluzione finale. Nella programmazione questo metodo corrisponde alla suddivisione del programma in moduli: programma principale, che richiama gli altri, e sottomoduli, che vengono chiamati sottoprogrammi, procedure, subroutine o semplicemente routine. Il programma principale richiama il modulo necessario in un certo punto tramite il nome (o una semplice istruzione); anche un sottomodulo può richiamarne altri (si parla anche in questo caso di nidificazione delle procedure); un modulo inoltre può venire richiamato in più punti, senza la necessità di dover ripetere le istruzioni che lo descrivono. Dividere il programma in moduli permette anche di conservare quelli che risolvono problemi che si presentano frequentemente, per riutilizzarli in altri casi, creando delle "librerie" di software.LA GESTIONE DELLE VARIABILI
I diversi moduli (programma principale e procedure) che compongono il programma sono composti da istruzioni che operano su dati; alcuni di questi possono essere necessari a più moduli, altri ad un solo modulo del programma. Si dice che le variabili sono globali quando vi si può fare riferimento da qualunque modulo del programma; si dice invece che sono locali quando sono utilizzabili solo all'interno di un modulo (e dei suoi sottomoduli). Il modo in cui vengono gestite le variabili varia da linguaggio a linguaggio. Alcuni consentono di utilizzare solo variabili globali; altri linguaggi permettono di definire variabili locali ad un modulo e di scambiare dati tra il modulo chiamante e il modulo chiamato tramite una lista di variabili (parametri) messe in comune.TIPI DI ALGORITMI
Gli algoritmi si possono dividere in: - algoritmi lineari: le istruzioni che compongono il programma vengono eseguite una volta sola; - algoritmi enumerativi: le istruzioni del corpo principale del programma vengono ripetute un numero prestabilito di volte; - algoritmi iterativi: le istruzioni del corpo principale del programma vengono ripetute un numero imprecisato di volte in base al verificarsi di certe condizioni; - algoritmi ricorsivi: il programma è suddiviso in moduli e ognuno di questi richiama se stesso.IMPLEMENTAZIONE DEL PROGRAMMA
Con il termine "implementazione" si intende la realizzazione del programma al computer, che comprende le fasi che vanno dalla codifica dell'algoritmo in un linguaggio di programmazione al completamento del programma, perfettamente funzionante.LA CODIFICA
Dopo aver completato la descrizione dell'algoritmo si può passare alla scrittura del programma in un linguaggio di programmazione, cioè alla "codifica" dell'algoritmo. Se il programma è suddiviso in moduli per la codifica si può procedere con il metodo top-down, partendo dal programma principale e procedendo via via con i moduli di livello inferiore o, in caso contrario, con il metodo bottom-up, partendo dai moduli a livello più basso e risalendo fino al programma principale. Ogni linguaggio di programmazione impone proprie regole per la codifica del programma, sia per quanto riguarda le istruzioni da usare, sia per il modo in cui le istruzioni devono essere scritte sulle righe. Il programma codificato viene immesso nel computer mediante un programma di utilità chiamato "editor", che può essere generico, oppure con funzioni specializzate per il tipo di linguaggio da codificare. Il programma inserito con l'editor può venire memorizzato in un file e richiamato successivamente per apportare modifiche o per proseguire con le altri fasi di implementazione. Il programma ottenuto con la codifica viene chiamato "programma sorgente"; il programma sorgente è quindi il programma scritto in linguaggio di programmazione, ma non ancora comprensibile al computer per l'esecuzione. Dopo la codifica si procede in modo diverso a seconda che si usi un linguaggio interpretato o un linguaggio compilato.SUGGERIMENTI PER LA CODIFICA
Oltre alle regole di codifica imposte dal linguaggio adottato è bene seguirne altre che, pur non essendo obbligatorie, permettono di rendere il programma più comprensibile. Per esempio: -scegliere nomi significativi per le variabili, le procedure, ecc. (per tutto ciò che dipende dal programmatore), in modo che il nome ricordi l'uso che si fa della variabile o dalla procedura; - scrivere le istruzioni con il metodo dell'identazione in modo da evidenziare le strutture di controllo; - fare ampio uso di commenti all'interno del programma per descrivere il significato delle istruzioni.L'EDITOR
L'editor è un programma di utilità che consente di inserire e memorizzare un testo o di richiamarlo successivamente per effettuare aggiunte o correzioni. Il testo in genere viene memorizzato carattere per carattere nel codice di rappresentazione usato dal computer (ASCII, EBCDIC). Gli editor possono appartenere a due tipi principali; editor di linea ed editor di video. Un editor di linea può presentare una lista di parte delle istruzioni del programma ma permette di lavorare su una riga per volta (per esempio l'editor Edlin del DOS). Un editor di video permette di vedere tutto il programma (anche se non può essere contenuto in una sola videata) offrendo semplici comandi per richiedere la visualizzazione di parti seguenti o precedenti (di solito si possono usare i tasti PageDown per passare alla videata successiva e PageUp per tornare a quella precedente); inoltre permette di effettuare direttamente le modifiche in qualsiasi punto del programma. In genere sono disponibili comandi per effettuare altre operazioni oltre all'inserimento e alla variazione del testo, come per esempio lo spostamento o la copia di parti del testo o la ricerca o sostituzione di stringhe di testo. Alcuni editor, orientati alla scrittura di programmi in un determinato linguaggio di programmazione, possono guidare l'inserimento delle istruzioni suggerendo le regole dell'incolonnamento da rispettare e talvolta effettuando un primo controllo formale sull'istruzione inserita.CONSIGLI PER L'USO DELL'EDITOR
L'inserimento del testo non avviene direttamente in un file su memoria di massa ma viene effettuato in memoria centrale; il testo viene trasferito sulla memoria di massa soltanto quando viene dato il comando di "salvare" il testo. Se per qualche motivo (per esempio una caduta improvvisa di corrente) si spegne il computer prima del salvataggio, si perde tutto quanto era stato scritto; la stessa cosa vale per le modifiche effettuate a un testo già memorizzato: le modifiche vengono apportate su una copia temporanea del file in memoria centrale e diventano effettive solo quando si procede a salvare il nuovo testo; conviene perciò quando si lavora con l'editor provvedere di tanto in tanto al salvataggio del lavoro per evitare spiacevoli sorprese. Alcuni editor permettono di ottenere al momento del salvataggio una copia della versione precedente del file; in questo modo se si hanno dei ripensamenti sulle modifiche fatte ( o se per qualche motivo il file si rovina) si può ripristinare la copia meno recente.I PROGRAMMI TRADUTTORI
Il computer è in grado di eseguire soltanto istruzioni in linguaggio macchina; il programma codificato in un linguaggio di programmazione viene tradotto in linguaggio macchina da programmatori traduttori chiamati interpreti o compilatori secondo il modo in cui operano. per ogni linguaggio esiste un programma traduttore specifico; per alcuni esiste un interprete, per altri un compilatore, a volte entrambi. Per esempio per i linguaggi Pascal e Cobol ci sono dei compilatori, per il linguaggio Basic è più diffuso l'utilizzo dell'interprete, sebbene esistano anche compilatori.PROGRAMMI IN LINGUAGGI INTERPRETATI
Se il programma viene scritto in un linguaggio che utilizza un interprete per la traduzione delle istruzioni in linguaggio macchina si può procedere subito all'esecuzione del programma. L'interprete procede istruzione per istruzione, provvedendo al controllo, alla traduzione e all'esecuzione dell'istruzione. Se l'interprete riscontra un errore formale nella scrittura di una istruzione, interrompe l'esecuzione del programma nel punto in cui si trova l'errore, con un messaggio di avvertimento.PROGRAMMI IN LINGUAGGI COMPILATI
Il compilatore controlla l'intero programma e, se non riscontra errori formali, traduce tutte le istruzioni in linguaggio macchina. Il programma in linguaggio macchina prodotto dal compilatore viene chiamato programma oggetto. Questo può essere eseguito soltanto in un ambiente collegato al compilatore, chiamato modulo run-time; è possibile rendere il programma eseguibile in modo indipendente dal modulo run-time procedendo alla fase chiamata "linkaggio" del programma, tramite il programma di utilità Linker. Il modulo run-time comprende il codice oggetto di sottoprogrammi necessari per lo svolgimento di funzioni di servizio, come per esempio le operazioni di input-output. Il linker collega al programma il codice oggetto necessario perché il programma possa essere eseguito in modo indipendente. Il programma eseguibile, preparato dal linker, viene chiamato anche modulo load e può essere memorizzato e richiamato all'occorrenza per l'esecuzione.VANTAGGI E SVANTAGGI DI COMPILATORI E INTERPRETI
Se si utilizza un linguaggio interpretato basta scrivere il programma e chiedere all'interprete di eseguirlo; se si usa un linguaggio compilato invece bisogna scrivere il programma, compilarlo, linkarlo e poi finalmente si può richiederne l'esecuzione. L'interprete quindi offre il vantaggio di lavorare in un ambiente interattivo per la realizzazione dei programmi, mentre con il compilatore il tempo necessario per completare il programma è maggiore (infatti ogni volta che si deve fare una correzione bisogna richiamare l'editor, poi di nuovo il compilatore, il linker e poi mandare in esecuzione il programma per controllare). L'interprete presenta però anche alcuni svantaggi. Quando esegue il programma deve prima tradurre ogni istruzione che incontra; le istruzioni di un ciclo vengono tradotte ogni volta che il ciclo viene percorso; il compilatore invece traduce ogni istruzione una sola volta, durante la creazione del modulo oggetto, e l'esecuzione risulta quindi più veloce. L'interprete traduce ed esegue il programma; per fare queste operazioni deve trovarsi nella memoria centrale insieme al programma che deve essere eseguito; un programma compilato, invece, dopo il linkaggio può essere eseguito autonomamente, richiedendo quindi una minore quantità di memoria libera. L'interprete traduce ( e quindi controlla) soltanto le istruzioni che deve eseguire; se durante le prove alcune istruzioni non vengono mai eseguite non vengono neppure controllate e potrebbero presentare errori che non vengono individuati; il compilatore invece traduce il programma soltanto se non ci sono errori formali e quindi dà una maggiore garanzia della sua correttezza. Conviene usare un interprete o un compilatore? L'ideale è avere a disposizione un interprete per lo sviluppo del programma, in modo da poter utilizzare l'ambiente interattivo per effettuare velocemente prove e correzioni, e un compilatore per creare un programma eseguibile, quando si è raggiunta la versione definitiva, per ottenere un programma che abbia bisogno di meno memoria e sia di esecuzione più veloce.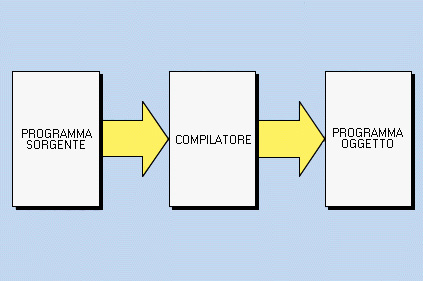
L'ESECUZIONE DEL PROGRAMMA
Eseguire il programma significa utilizzarlo per risolvere un caso particolare del problema per cui è stato preparato. L'utente deve fornire i dati iniziali (input del programma) e dopo l'elaborazione ottiene i risultati che aspettava (output del programma). Per esempio se è stato realizzato un programma per la somma di due numeri, l'utente inserisce i due numeri che desidera sommare e riceve in output il risultato dell'operazione. Il modo in cui l'utente e il programma interagiscono tra loro (messaggi di richiesta, modo in cui i dati devono essere inseriti, modo di emissione dei risultati) costituisce l'interfaccia tra programma e utente.Realizzazione di un programma con un compilatore
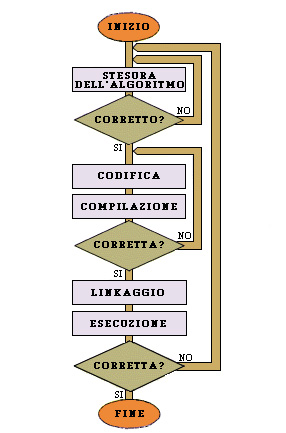
GLI ERRORI
Durante le fasi di creazione del programma si possono verificare diversi tipi di errori. Gli errori più semplici da correggere sono gli errori formali, segnalati dal programma traduttore (l'interprete o il compilatore). Questi errori impediscono al compilatore di produrre il codice oggetto e all'interprete di proseguire nell'esecuzione del programma. Gli errori di questo tipo comprendono gli errori di scrittura più banali (come scrivere una lettera al posto di un'altra), gli errori nella punteggiatura richiesta dal linguaggio, gli errori nella sintassi delle istruzioni (per esempio tralasciando una parola necessaria), gli errori nella definizione delle variabili (utilizzare come nome per una variabile una parola riservata). Un'altra classe è quella degli errori che si verificano durante l'esecuzione del programma a causa di un'operazione non consentita; per esempio, la richiesta di eseguire una divisione per zero. L'ultimo e più grave tipo di errore comprende tutti quelli che fanno ottenere risultati non corretti; in questo caso il programma funziona, ma non nel modo che si desidera e non compie il lavoro per cui è stato progettato. Alcuni errori di esecuzione possono essere dovuti anche all'inserimento di dati di input errati da parte dell'utente; il programma dovrebbe sempre, per quanto possibile, controllare l'esattezza dei dati inseriti, segnalando gli errori e permettendo di correggere i dati errati.IL DEBUG
Viene chiamata debug la fase di prova del programma, durante la quale vengono individuati e corretti gli errori che impediscono il corretto funzionamento del programma. Per avere la certezza assoluta che il programma sia perfettamente esatto bisognerebbe verificare i risultati ottenuti per qualsiasi combinazione di dati di input; questo ovviamente è impossibile anche per programmai non troppo complicati poiché le combinazioni di valori ammessi in genere sono moltissime se non infinite. Si procede quindi provando il programma su una serie di dati campione, caratteristici delle diverse situazioni che si possono verificare durante l'esecuzione. I risultati prodotti in output dal programma vengono controllati con quelli che ci si aspettava di ricevere; se ci sono differenze, anche minime, bisogna effettuare altre prove per individuare esattamente l'errore che le provoca. Dopo aver apportato le correzioni previste bisogna ripetere tutte le prove effettuate, con gli stessi dati, per verificare se si è effettivamente riusciti a correggere il programma.LA SCELTA DEI DATI CAMPIONE
I dati campione per la prova del programma possono essere scelti in base alla struttura del programma, scegliendo cioè quelli che permettano di esplorare i diversi rami delle strutture condizionali e il corpo delle strutture cicliche oppure, in base alle funzioni del programma, scegliendo dapprima valori semplici e poi valori realistici, e provando inoltre i valori estremi (che rappresentano situazioni limite, che non rientrano nel generico flusso di esecuzione) e valori illegali (che possono cioè causare errori durante l'esecuzione) per verificare se il programma è in grado di gestire situazioni anomale.LA TRACCIA DEL PROGRAMMA (O TRACE)
Per controllare il programma si possono seguire passo per passo le istruzioni, partendo da alcuni valori di input, annotando ad ogni passo il valore che assumono le variabili. Questo procedimento viene chiamato traccia o trace e può essere eseguito sia sulla descrizione dell'algoritmo che sul programma ( anche durante l'esecuzione del programma, eventualmente inserendo le istruzioni che visualizzino il contenuto delle variabili in punti intermedi dell'elaborazione).GLI AMBIENTI DI DEBUG
Alcuni linguaggi mettono a disposizione istruzioni apposite per eseguite il debug del programma. Esistono anche particolari ambienti che permettono di eseguire in modo interattivo il debug del programma, senza dover aggiungere nuove istruzioni al programma. E' possibile allora seguire automaticamente la traccia del programma o di una parte di esso, interrompere l'elaborazione in un punto desiderato, visualizzare il contenuto di una variabile, o addirittura modificarne il contenuto prima di riprendere l'esecuzione.LE CORREZIONI AL PROGRAMMA
Se si deve modificare l'algoritmo, le correzioni vanno apportate sulla descrizione dell'algoritmo stesso e non direttamente sul programma, per poter valutare in modo migliore gli effetti che potrebbero avere (ci potrebbero essere effetti indesiderati in altri punti del programma). Quando si apportano delle modifiche al programma sorgente, queste diventano subito effettive se si lavora con un interprete; se si lavora con un compilatore si vede il risultato delle correzioni soltanto dopo aver ricompilato e linkato il programma.LA DOCUMENTAZIONE
Ritornare ad esaminare un programma, anche breve, scritto qualche tempo prima è quasi sempre un dramma. Fare anche una semplicissima modifica diventa un'impresa veramente ardua, fonte di innumerevoli errori e di disperazione. Per limitare questo grosso problema è importante documentare tutto il lavoro svolto. La documentazione è importantissima soprattutto in ambiente aziendale, dove la fase di manutenzione del programma ( revisione, modifica, adattamenti, ecc.) è ancora più lunga della fase di realizzazione e dove spesso non è la stessa persona, o gruppo di persone, che ha creato il programma a occuparsene in seguito. La documentazione in genere comprende: - la descrizione del problema da risolvere; - la descrizione dei dati, precisando per ognuno di essi il nome e il tipo della variabile e il significato che la variabile assume; - la descrizione dell'algoritmo (per esempio con il flow-chart o la pseudocodifica); - il listato della codifica del programma; - le prove fatte per la verifica. Se il programma si compone di più moduli, le informazioni fondamentali da indicare per ogni modulo sono: - la funzione; - i parametri, cioè i valori che vengono scambiati con il programma chiamante.IL MANUALE DELL'UTENTE
Per chi usa il programma la documentazione fondamentale è costituita dal manuale dell'utente o manuale d'uso che deve contenere almeno: - le istruzioni per avviare l'esecuzione del programma; - le istruzioni da seguire durante le varie fasi di esecuzione; - la spiegazione degli eventuali messaggi di errore presentati dal programma.IL PROGRAMMATORE E L'UTENTE
Il programmatore è la persona che descrive l'algoritmo per la soluzione di un problema, o meglio ne realizza il programma corrispondente al computer. L'utente è la persona che utilizza il programma per ottenere i risultati desiderati. Il programmatore può essere anche utente del suo programma, ma in generale un utente non è un programmatore, non sa come sia fatto un programma e spesso non ha neppure nozioni di programmazione o di informatica; per utilizzare il programma ha quindi bisogno di istruzioni dettagliate per sapere cosa fare in ogni circostanza.INGEGNERIA DEL SOFTWARE
Con il termine ingegneria del software si intende un insieme di tecniche di standardizzazione dell'attività di produzione dei programmi, con metodi di sviluppo e di documentazione basati anche su principi matematici. Il primo passo verso l'ingegneria del software è stao l'introduzione delle tecniche di programmazione strutturata, e dei metodi di sviluppo top-down che aiutano a sviluppare il programma in maniera modulare e razionale. In seguito si sono sviluppate delle vere e proprie filosofie di programmazione, tra cui le più note, soprattutto per lo sviluppo di programmi di gestione aziendale, sono le metodologie di Warnier e di Jackson.IL METODO WARNIER
E' un metodo che utilizza un linguaggio lineare (non grafico) per la rappresentazione e documentazione dell'algoritmo e si basa su tecniche top-down e di programmazione strutturata. Un blocco logico viene indicato con una parentesi graffa. Più livelli di parentesi graffe sviluppano successivamente blocchi di istruzioni. Per rappresentare le strutture fondamentali di programmazione (sequenziale, alternativa, iterativa) viene utilizzata la simbologia illustrata in figura.Simbologia usata nel metodo Warnier
IL METODO JACKSON
E' un metodo grafico per la rappresentazione e la documentazione della struttura dei dati e dell'algoritmo che si basa su tecniche top-down e di programmazione strutturata. La rappresentazione grafica si basa sullo sviluppo di un diagramma ad albero. Per rappresentare le strutture fondamentali di programmazione si usa la notazione illustrata in figura.Simbologia usata nel metodo Jackson
I CASE PER LA REALIZZAZIONE DI PROGRAMMI
I CASE (Computer Aided Software Engineering) sono strumenti (software) che permettono di aiutare il progettista nelle fasi di sviluppo dei programmi. Offrono un aiuto nella progettazione del programma e a volte sono capaci di realizzarne automaticamente la codifica in alcuni linguaggi tradizionali (come Cobol, RPG o C).ALGORITMI RICORSIVI
Un algoritmo è ricorsivo quando utilizza delle procedure che al loro interno richiamano se stesse. In pratica si può dire che, durante la descrizione di un procedimento, ne viene richiesta l'intera ripetizione. L'algoritmo non deve però continuare a ripetere il procedimento all'infinito; bisogna quindi che le procedure ricorsive soddisfino delle condizioni che garantiscano la fine del procedimento; queste si possono riassumere cosi: - ogni chiamata successiva della procedura deve applicarsi ad un sottoinsieme dei dati di quella precedente o a valori minori; - deve essere definita una condizione di terminazione delle ripetizioni, chiamata base della ricorsione. Non tutti i linguaggi di programmazione permettono l'uso della ricorsività; in ogni caso una struttura ricorsiva può sempre essere descritta con un procedimento iterativo (che utilizza le strutture di controllo cicliche). La descrizione del procedimento iterativo è spesso più complicata di quella del procedimento ricorsivo, che presenta una maggior semplicità di formulazione. Al contrario però, verificare che l'algoritmo sia corretto risulta più semplice nella versione iterativa che non nella versione ricorsiva.RICORSIONE SEMPLICE E INDIRETTA
La ricorsione in un programma può essere semplice se una procedura richiama se stessa direttamente, o indiretta se la procedura richiama un altra procedura che a sua volta richiama la prima. (Per esempio la procedura A richiama la procedura B e la procedura B richiama la procedura A).LA COMPUTABILITA'
Un problema si dice computabile se la sua soluzione può essere descritta mediante un algoritmo (cioè un procedimento che termini dopo un numero finito di passi, descritto in modo deterministico, effettivamente eseguibile dall'esecutore e generale per la classe di problemi considerata). Esistono anche dei problemi che non sono risolvibili con un procedimento algoritmico; questi problemi si dicono non computabili. E' difficile immaginarsi dei problemi non computabili eppure essi sono addirittura più numerosi di quelli computabili.TIPI DI PROBLEMI IN BASE ALLA COMPUTABILITA'
Per poter affermare che un problema è non computabile, e quindi insolubile, bisogna "dimostrare" che non esite una soluzione algoritmica. Ci sono dei problemi per cui non si riesce a trovare una soluzione algoritmica, ma non si riece nemmeno a dimostrare che non esista una soluzione. I problemi si possono quindi dividere in: - problemi computabili (esiste una soluzione algoritmica); - problemi non computabili (è dimostrato che non esiste una soluzione algoritmica); - problemi che vengono considerati non computabili ma per cui potrebbe essere trovata prima o poi una soluzione.LA COMPLESSITA' COMPUTAZIONALE
Si definisce complessità di un algoritmo la quantità di tempo che occorre alla CPU per eseguire il programma relativo. Per risolvere un problema possono essere disponibili algoritmi diversi (per esempio per ordinare un vettore sono disponibili molti metodi); si dice complessità computazionale di un problema la complessità dell'algoritmo più efficiente per risolvere il problema (cioè quello che viene eseguito più velocemente). Il calcolo del tempo di esecuzione di un algoritmo viene fatto in modo approssimato, determinandone l'ordine di grandezza e non il valore effettivo (che non potrebbe essere calcolato in modo generale, poiché dipende per esempio dal linguaggio scelto per la codifica, dal compilatore o interprete usato, dalla macchina su cui viene eseguito il programma ecc.). La misura del tempo di esecuzione di un algoritmo e quindi la complessità dell'algoritmo viene espressa in funzione della dimensione dei dati di input (numero di elementi di un vettore, numero di cifre di un valore ecc.) o in certi casi addirittura in funzione dello stesso valore di input. La complessità dell'algoritmo può essere espressa dalla funzione C(n) che rappresenta il tempo impiegato per l'esecuzione dell'algoritmo applicato a dati di input di dimensione n.COMPLESSITA' DEI PROBLEMI E PROBLEMI INTRATTABILI
Le complessità più comuni sono: - la complessità costante: il tempo di esecuzione dell'algoritmo non dipende dall'input ma si mantiene costante; è il miglior caso possibile. -la complessità logaritmica: il tempo di esecuzione aumenta secondo il logaritmo della dimensione dei dati di input; il logaritmo è una funzione i cui valori aumentano molto lentamente quindi un algoritmo con complessità logaritmica è uno tra i casi migliori. - la complessità lineare: il tempo di esecuzione aumenta in modo proporzionale alla dimensione dei dati di input. - la complessità polinomiale: il tempo di esecuzione aumenta in modo proporzionale a una potenza della dimensione dei dati di input. - la complessità esponenziale: la dimensione dei dati di input compare nell'esponente della funzione per il calcolo del tempo; è tra i casi peggiori; il tempo aumenta molto rapidamente anche per piccoli incrementi della dimensione dei dati di input. In base alla complessità computazionale i problemi vegono separati in: - problemi la cui complessità è al più polinomiale; - problemi con complessità esponenziale. I problemi con complessità esponenziale vengono detti intrattabili poiché anche per input di piccole dimensioni il tempo necessario per ottenere una soluzione risulta troppo elevato (quindi non sono effettivamente risolvibili). Il fatto che questi problemi siano intrattabili non dipende dall'attuale velocità della CPU dei computer ma proprio dalla natura del problema. Infatti, anche aumentando di migliaia di volte la velocità della CPU, i valori di n per cui il problema potrebbe essere risolto aumenterebbero solo di qualche unità. Pur essendo computabili i problemi risolvibili con algoritmi di complessità esponenziale non sono poi effettivamente risolvibili poiché richiederebbero tempi di elaborazione troppo elevati (anche dell'ordine di secoli). Un problema si dice allora effettivamente computabile se la sua complessità è al più polinomiale. Alcuni problemi ammettono soluzioni con complessità polinomiale anche se le migliori soluzioni hanno complessità esponenziale (sono intrinsecamente esponenziali; per es. il problema del gioco degli scacchi). Altri vengono ritenuti di complessità esponenziale poiché non si è ancora trovato un algoritmo di complessità polinomiale, anche se non si è dimostrata rigorosamente la complessità esponenziale del problema (si dovrebbe cioè "dimostrare" che non esiste una soluzione polinomiale).![]()
Guadagnare navigando! Acquisti prodotti e servizi.
Guadagnare acquistando online.
![]()
ALGORITMI EURISTICI
Non esistono regole generali che permettono di trovare automaticamente la soluzione di un problema: risolvere un problema è un processo creativo, che non è detto abbia sempre esito positivo; non è detto, cioè, che sia sempre possibile definire una sequenza di operazioni che risolva un problema. In alcuni casi la soluzione può essere cercata con un procedimento euristico. Un algoritmo euristico è un procedimento che ricerca la soluzione per tentativi ed errori, che non garantisce il raggiungimento di una soluzione ma offre solo un metodo per la ricerca della soluzione stessa. Per poter definire un algoritmo euristico si devono realizzare delle tecniche di backtracking, cioè avere la possibilità di ritornare sui propri passi per scegliere una soluzione alternativa nel momento in cui ci si accorge che il cammino percorso non è valido. Si può risolvere con un algoritmo euristico per esempio il problema di spostare un cavallo da una casella ad un'altra della scacchiera; si possono provare varie mosse, tornando indietro se ci si accorge che le mosse compiute non portano ad alcuna soluzione.LA MACCHINA DI TURING
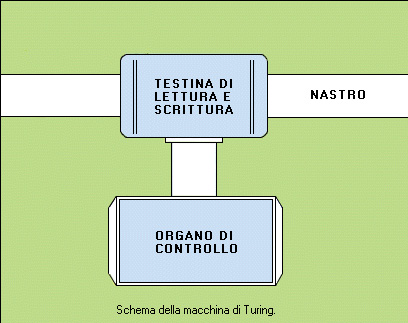
La macchina di Turing è una macchina astratta (non costruita praticamente, ma definita solo a livello concettuale) formata da un nastro infinito, una testina di lettura e scrittura e un organo di controllo. Il nastro è diviso in caselle; ogni casella può contenere un simbolo dell'alfabeto della macchina, che ne comprende anche uno che indica la casella vuota. La testina di lettura e scrittura, partendo da una casella iniziale, può spostarsi a destra o a sinistra ed effettuare operazioni di lettura o scrittura. L'organo di controllo è dotato di una memoria interna che può assumere un numero finito di stati diversi. In un certo istante la testina è posizionata su una casella che contiene un simbolo dell'alfabeto e la memoria interna si trova in uno dei possibili stati. In base alle combinazioni dei simboli incontrati nelle caselle e degli stati in cui si trova la memoria viene definito il comportamento della macchina. Per descrivere il comportamento della macchina si devono specificare ad ogni passo tre azioni: 1) il simbolo che deve essere scritto nella casella su cui si trova la testina di lettura e scrittura; 2) la direzione in cui si deve muovere la testina (destra o sinistra); 3) il nuovo stato in cui si deve passare. Ogni problema, per essere risolto, richiede una particolare macchina di Turing, con relativo alfabeto, insieme di stati e una particolare funzione che associ ad ogni combinazione di simbolo dell'alfabeto e stato della memoria le tre azioni da eseguire. Se la macchina di Turing nel suo procedimento si arresta dopo un numero finito di passi si dice che le informazioni contenute sul nastro sono applicabili alla macchina o che il problema proposto è computabile, (la macchina di Turing può risolvere la classe di cui il problema proposto fa parte). Le informazioni che si trovano sul nastro quando la macchina si ferma costituiscono la soluzione del problema. Se una macchina di Turing, una volta iniziato il suo funzionamento, non riesce più a fermarsi significa che le informazioni sulle quali sta operando non sono applicabili ad essa (o che il problema non è computabile). La tesi di Turing afferma che per ogni algoritmo è possibile definire una macchina di Turing, cioè che algoritmi e macchine di Turing sono logicamente equivalenti. Questa tesi non è dimostrata; non è stato mai trovato però un controesempio che ne dimostri l'infondatezza, cioè non è stato mai trovato un algoritmo per il quale non sia possibile costruire una macchina di Turing in grado di realizzarlo.LA MACCHINA DI TURING UNIVERSALE
Una macchina di Turing, definita in modo adeguato, è in grado di eseguire qualsiasi algoritmo. Si può allora pensare di realizzarne una capace di simulare il funzionamento di tutte le possibili macchine di Turing, quindi in grado di eseguire gli algoritmi di tutte le possibili classi di problemi computabili. Una macchina di questo tipo viene chiamata macchina di Turing universale. Essa può essere pensata come una macchina di Turing con due nastri e due testine di lettura/scrittura. Sul primo nastro viene memorizzato il modo in cui deve operare la macchina, cioè quali azioni devono essere compiute per ogni combinazione di simbolo incontrato nella casella del nastro e stato della memoria, mentre il secondo nastro è quello su cui si scrivono i dati e su cui alla fine si trovano i risultati. La macchina universale consulta il primo nastro durante il funzionamento per sapere di volta in volta che cosa fare (il primo nastro contiene quindi il "programma" da eseguire). Il moderno calcolatore a programma memorizzato può essere paragonato a una macchina di Turing universale. La differenza fondamentale tra computer e macchina di Turing è che quest'ultima ha una memoria esterna infinita (il nastro) mentre il calcolatore opera sempre con una memoria finita.Schema della macchina di Turing
![]()
![]()
Enciclopedia termini lemmi con iniziale a b c d e f g h i j k l m n o p q r s t u v w x y z
Storia Antica dizionario lemmi a b c d e f g h i j k l m n o p q r s t u v w x y z
Dizionario di Storia Moderna e Contemporanea a b c d e f g h i j k l m n o p q r s t u v w y z
Lemmi Storia Antica Lemmi Storia Moderna e Contemporanea
Dizionario Egizio Dizionario di storia antica e medievale Prima Seconda Terza Parte
Storia Antica e Medievale Storia Moderna e Contemporanea
Dizionario di matematica iniziale: a b c d e f g i k l m n o p q r s t u v z
Dizionario faunistico df1 df2 df3 df4 df5 df6 df7 df8 df9
Dizionario di botanica a b c d e f g h i l m n o p q r s t u v z
![]()
Rai Scuola I pitagorici e la scoperta dei numeri irrazionali
Matematica
I Numeri complessi I Numeri Immaginari I numeri Relativi I Numeri Naturali I Numeri Reali
Ripasso di matematica Aritmetica e numeri
Aritmetica Geometria Informatica
Geometria Piana e Solida Informatica Media Ecdl
Prisma retto Cilindro Superficie e Volume Aritmetica Geometria Informatica Dizionario Lessicale di Geometria
Geometria Piana e Solida Informatica Media Ecdl
Geometria Piana e Solida
Elementi Fondamentali della Geometria Gli Angoli Il Triangolo Il Cerchio Linee sul Piano Quadrilateri e Poligoni Superficie dei Poligoni Cilindri e Prismi Coni e Piramidi Gli Esaedri La Sfera Geometria Solida Nozioni Generali Solidi di Rotazione
